
Demo
Note: I am using a free tier option on Heroku to host my API as a service, this means it will shut itself down and will be slow for the first attempt as it starts up the container.
Note also: If you’re face is not detected it may be because part of your face is covered by your hair. Also the models used in this API use DLib’s frontal face detector. Which means if you are not facing the camera it may not detect your face. I also restricted the number of faces to only allow one face to save computation.
More important note: This will not work on mobiles as the javascript needs updating for full cross browser support.
Load DemoInspiration
The inspiration for this article came from MachineBox where they offer their products free for open source projects. MachineBox are really making waves with their on-premises containerisation of machine learning capabilities. The particular inspiration for this blog came from their FaceBox product which is incredibly powerful and simple to run. However, I wanted to add in some extra features into my API such as Landmark Detection and Pose Estimation.
You can see the whole project over on my GitHub repo
High Level Overview
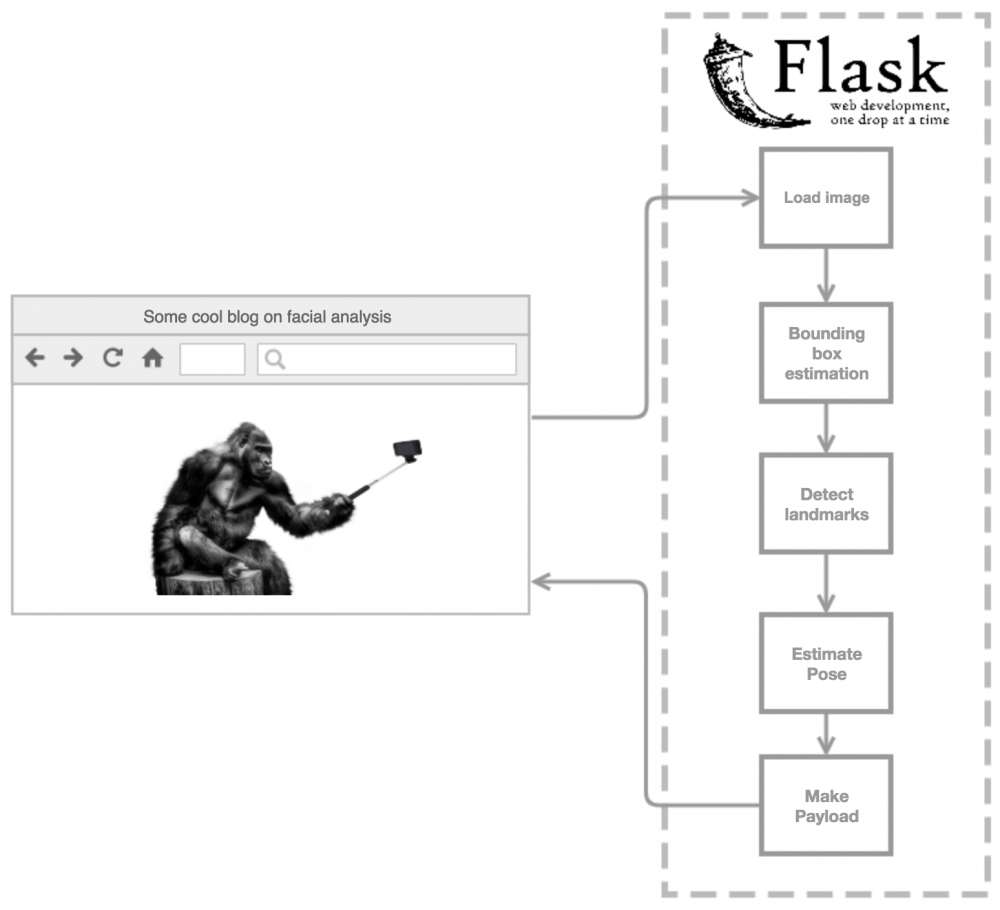
Building an Environment
As usual we will be using Docker to create a reproducable environment. By doing this from the outset of development we can ensure that the API will be horizontally scalable, that way, if we were to somehow get over 500 requests per minute, we could just spin up another container. We also want to make this container as light as possible so we should start from an alpine Docker image and build it up from there.
Note: If this was to be productionalised it could be made even lighter by reducing the number of layers and removing any unnessesary libraries.
|
|
For conveniance we can also create a docker-compose file to save the user having to have knowledge of Docker to be able to start this container with the configurations.
|
|
Creating a Flask API
This should be relatively simple implementation of Flask, as we always expect to recieve an image and we will send back a payload describing the image. We will seperate this out into a file called server.py which will import the Facial Analysis object that we create in the next section.
Note we also import two other files: settings.py and helpers.py. The helper function is a wrapper that will send an abort message (400 error) if at any point the Facial Analysis fails. We also pull through a variable from settings.py whether we will be upsampling the image when running the bounding box detection.
|
|
Developing a Facial Analysis Object
Since we may be getting multiple requests at a time and we want to implement multi-threading to improve the performance of our API it makes sense to create an instance with arributes and methods for each of the algorithms we will be using. Therefore we will be creating a Facial Analysis object. We will be incorporating three main methods; bounding box estimation, facial landmark detection and pose estimation.
Note that we will have some dependancies to manage and hence will have to split the multithreading into different sections. Pose estimation is dependant on the facial landmarks, which are also dependant on the bounding box estimation.
Before we can get to all of these fancy algorithms we have to be able to load the image from our API. We will do this along with some other convenience operations when we initialise the object.
|
|
Bounding Box Estimation
Theory – see pyimagesearch
|
|
Facial Landmark Detection
Theory – see learnopencv
|
|
Pose Estimation
Theory – see learnopencv
|
|
Designing a Front End
I’m not going to claim to have spent the time in designing the front end that I used! I started off by using Dan Markov’s “Take a selfie with javascript” jsfiddle. Once we have this set up we simplay have to add an API call when the photo is taken. We can do this using an AJAX call, once the photo has been taken it will be stored in a canvas object which we can convert to a blob and send that to our API.
Note: drawResponse is a function that draws the bounding box, pose and facial landmarks ontop of our canvas.
Note: showResponse is a function that displays the response from the API using renderjson.js below the image.
Note: We also define a modal using the tingle.js library
|
|